Alex Soto & Markus Eisele
RAG like a hero with Docling
#1about 3 minutes
Using RAG to enrich LLMs with proprietary data
Retrieval-augmented generation (RAG) is the key to making large language models useful for enterprises by providing them with up-to-date, proprietary information.
#2about 4 minutes
The challenge of parsing complex document structures
Simple document parsers can misinterpret layouts like multi-column text, leading to corrupted data and incorrect outputs from the language model.
#3about 3 minutes
Using Docling to convert documents into structured formats
Docling is an open-source tool that acts like an advanced OCR service, converting various binary document formats into a structured, parsable tree.
#4about 7 minutes
Demo of a basic RAG ingestion pipeline
A live demonstration shows how a Quarkus application uses Docling to ingest a PDF, generate embeddings, and store the resulting chunks and vectors in Redis.
#5about 3 minutes
Securing RAG against data poisoning and leaks
To prevent data poisoning and sensitive data leaks, it is crucial to sanitize documents, verify their signatures, and use tools for PII masking.
#6about 4 minutes
Mitigating vector store attacks and encryption challenges
Vector stores are vulnerable to attacks like close vector modification and reversal, and standard encryption breaks vector distance, requiring specialized solutions.
#7about 5 minutes
Demo of a secure ingestion pipeline in action
A final demonstration showcases a secure pipeline that verifies document signatures, anonymizes sensitive data, and encrypts vectors before storing them.
Related jobs
Jobs that call for the skills explored in this talk.
Matching moments
07:55 MIN
Demo: Implementing RAG with LangChain4J and a vector database
Langchain4J - An Introduction for Impatient Developers
Unlock Moments
Create a free account to watch a limited number of Moments each month.
Upgrade to PRO for unlimited access to the full archive.
Upgrade to PRO for unlimited access to the full archive.
You have an account? Log in

02:00 MIN
Addressing unique security risks in RAG systems
Beyond the Hype: Building Trustworthy and Reliable LLM Applications with Guardrails
Unlock Moments
Create a free account to watch a limited number of Moments each month.
Upgrade to PRO for unlimited access to the full archive.
Upgrade to PRO for unlimited access to the full archive.
You have an account? Log in

03:19 MIN
Using RAG for secure enterprise data integration
Bringing AI Everywhere
Unlock Moments
Create a free account to watch a limited number of Moments each month.
Upgrade to PRO for unlimited access to the full archive.
Upgrade to PRO for unlimited access to the full archive.
You have an account? Log in
04:10 MIN
A deep dive into retrieval-augmented generation
Lies, Damned Lies and Large Language Models
Unlock Moments
Create a free account to watch a limited number of Moments each month.
Upgrade to PRO for unlimited access to the full archive.
Upgrade to PRO for unlimited access to the full archive.
You have an account? Log in
05:31 MIN
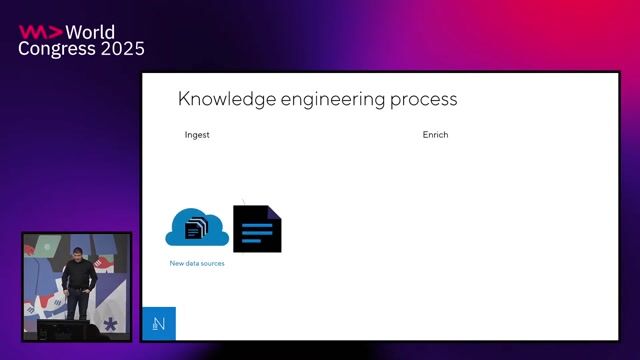
Understanding retrieval-augmented generation (RAG)
Exploring LLMs across clouds
Unlock Moments
Create a free account to watch a limited number of Moments each month.
Upgrade to PRO for unlimited access to the full archive.
Upgrade to PRO for unlimited access to the full archive.
You have an account? Log in

02:05 MIN
Simplifying retrieval-augmented generation (RAG) pipelines
One AI API to Power Them All
Unlock Moments
Create a free account to watch a limited number of Moments each month.
Upgrade to PRO for unlimited access to the full archive.
Upgrade to PRO for unlimited access to the full archive.
You have an account? Log in
03:31 MIN
Visualizing the end-to-end RAG architecture
Building Blocks of RAG: From Understanding to Implementation
Unlock Moments
Create a free account to watch a limited number of Moments each month.
Upgrade to PRO for unlimited access to the full archive.
Upgrade to PRO for unlimited access to the full archive.
You have an account? Log in

09:46 MIN
Code walkthrough for building a RAG-based chatbot
Creating Industry ready solutions with LLM Models
Unlock Moments
Create a free account to watch a limited number of Moments each month.
Upgrade to PRO for unlimited access to the full archive.
Upgrade to PRO for unlimited access to the full archive.
You have an account? Log in
Featured Partners
Related Videos
 21:17
21:17Carl Lapierre - Exploring Advanced Patterns in Retrieval-Augmented Generation
Carl Lapierre
 26:25
26:25Building Blocks of RAG: From Understanding to Implementation
Ashish Sharma
 28:57
28:57Accelerating GenAI Development: Harnessing Astra DB Vector Store and Langflow for LLM-Powered Apps
Dieter Flick & Michel de Ru
 28:04
28:04Build RAG from Scratch
Phil Nash
 29:11
29:11Large Language Models ❤️ Knowledge Graphs
Michael Hunger
 29:00
29:00Beyond the Hype: Building Trustworthy and Reliable LLM Applications with Guardrails
Alex Soto
 26:42
26:42Building AI Applications with LangChain and Node.js
Julián Duque
 31:59
31:59Langchain4J - An Introduction for Impatient Developers
Juarez Junior
Related Articles
View all articles



From learning to earning
Jobs that call for the skills explored in this talk.


Testsieger.de Vergleichsportal GmbH
Osnabrück, Germany
MySQL
Pandas
PyTorch
Data analysis
Machine Learning